Image Compression with Autoencoders (Work in Progress)
My Latest Projects | | Links:
Idea
File compression is an important aspect in cloud computing and in Content Delivery Network (CDN). For example, in a CDN system, when a user asks for a new file or image, the request would be propagated to the root server which would retrieve the file from the database then transfer it back to an edge server the user has access to. Now, if this data is requested multiple times, it would be stored in a cache server close to the client to speed up access and reduce demand on the company’s bandwidth. These servers usually work in tandem with reverse proxies or load balancers to ensure efficiency and improve performances.
Now for the case of images, a simple picture may have different resolutions requested by different users that would need to be cached. Say User A asks for a medium resolution picture which is requested from the root server then stored in the cache, and User B asks for the same image, but in a higher resolution which will also be stored in the cache. Storing multiple images in a cache servers can prove to be costly, especially if there are many nodes in the network. To reduce the size of these nodes, we can compress the images, but what can we do about the fact that we have multiple resolutions? We have the same picture, but in two different resolutions stored in the cache. Is there a way to save only 1 compressed representation of that image in the cache and have the choice to uncompress it to one of the 2 resolutions when the image needs to be retrieved?
Well, the solution I am currently studying is to train a network to compress medium resolution images, then to train a second network to compress high resolution images, and finally train a third network to use the compressed high resolution of the image and generate its medium resolution with high accuracy using AutoEncoders. This way, only high resolution images would have to be stored in the cache servers. Then, if this works the next step would be to train a generative network to use the compressed medium resolution images to get a high resolution image:
- Network to compress/decompress medium resolution images
- Network to compress/decompress high resolution images
- Network to retrieve medium resolution image from compressed high resolution image
- 3b. Network to generate high resolution image from compressed medium resolution image
The findings of this project could then be extended to videos—which are some of the largest files in CDNs. This idea is explored in the paper Deep Generative Video Compression which explores the compression of videos using Variational Autoencoders.
Deep Learning Task
Goal: Find compressed knowledge representation of the original input
The goal in the first step is to find the latent, or compressed, representation of the images we want to save in the cache.
How: By training Autoencoders on a large bank of images
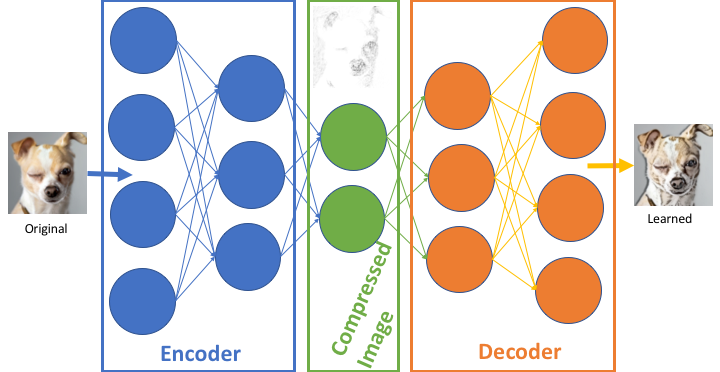
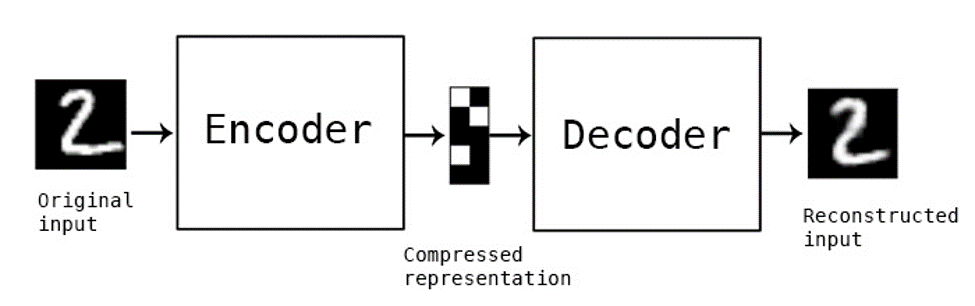
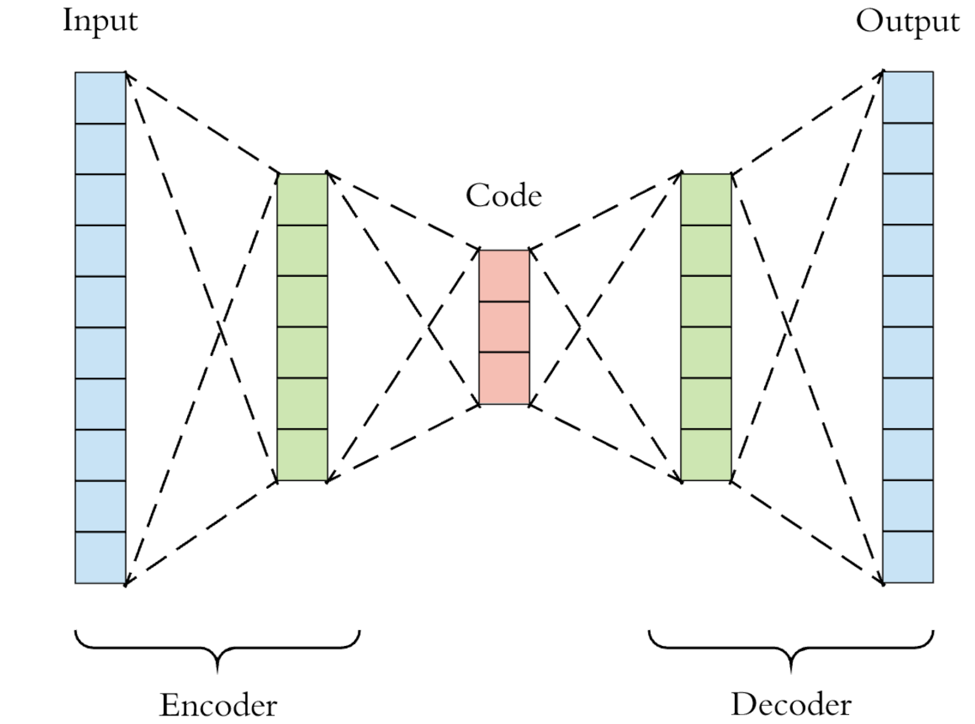
This can be done notably by using a specific type of artificial neural network: the autoencoder. The autoencoder is a technique used to discover efficient data codings in an unsupervised manner. The aim of an autoencoder is to learn a representation for a set of data (encoder), typically for dimensionality reduction, then to learn how to reconstruct the data back from the reduced encoded representation to a representation that is as close to the original input as possible (decoder).
Methods
For this task, 3 types of Autoencoders can be used:
Fully connected autoencoder
In the case of the fully connected autoencoder, both the encoder and decoder are fully-connected feedforward neural networks. First the input passes through the encoder to produce the code. Then, the decoder which has a similar neural network structure produces the output only using the code. The goal is to get an output identical with the input. Note that the decoder architecture is the mirror image of the encoder. This is not a requirement but it’s typically the case. The only requirement is the dimensionality of the input and output needs to be the same.
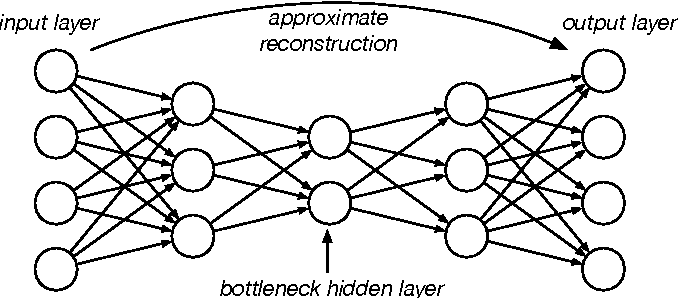
However, this model would not suited for our task as the number of parameters in the fully connected layers would be way too large since we are dealing with images. For example, the number of parameters in the first layer assuming only 100 neurons and a 172x172 colored image (rgb) would be 172 x 172 x 3 x 100 + 100 = 8,875,300 parameters only for the first layer.
Convolutional autoencoders
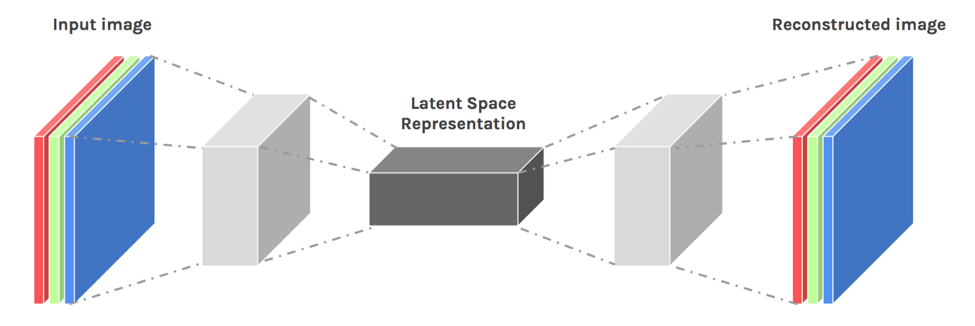
Unlike the fully connected autoencoder, the convolutional autoencoder keep the spatial information of the input image data as they are, and extract information efficiently in what is called the convolution layer. This way, the number of parameters needed using the convolutional autoencoder is greatly reduced. Furthermore, it also retains the spatial relationships in the data.
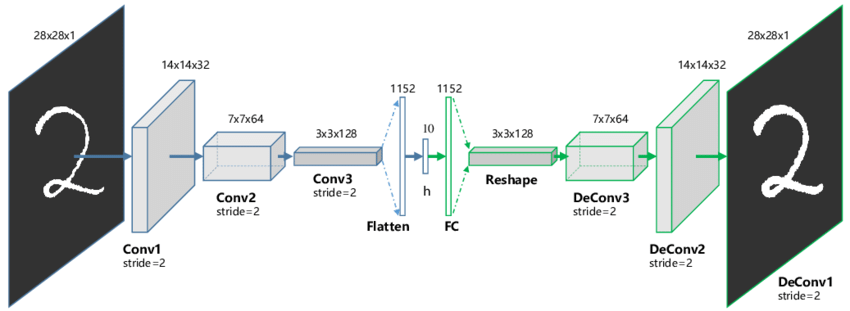
This is the model currently in use for this first attempt at solving the representation learning task.
Variational autoencoders
A variational autoencoder can be defined as being an autoencoder whose training is regularised to avoid overfitting and ensure that the latent space has good properties that enable generative process. Just as a standard autoencoder, a variational autoencoder is an architecture composed of both an encoder and a decoder and that is trained to minimise the reconstruction error between the reconstructed data and the initial data. However, rather than building an encoder which outputs a single value to describe each latent state attribute, we formulate our encoder to describe a probability distribution for each latent attribute. This introduces some regularisation in the latent space. In this case, the encoder model can be referred to as the recognition model whereas the decoder model can be referred to as the generative model.
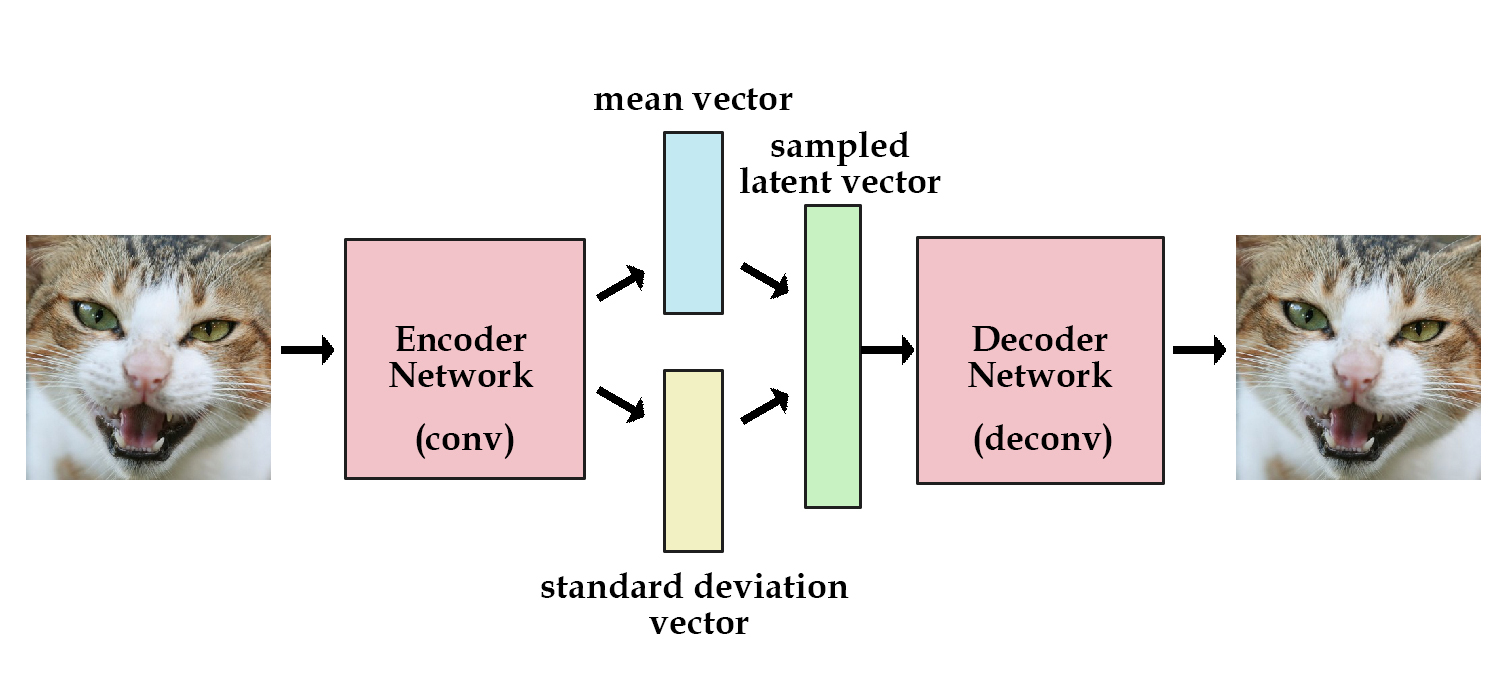
Unlike convolutional autoencoders, this model is generally used as a generative model. However, it could be an interesting alternative solution.
Data from DIV2K Dataset
In order to train this model and provide a proof of concept, I decided to opt for the DIVerse 2K resolution high quality images (DIV2K) dataset. The DIV2K dataset consist of RGB images with a large diversity of contents. It includes:
- Numerous images duplicated in different resolutions
- For each resolution: 800 images for the training set
- 100 images for the validation set
- 100 images for the testing set


The dataset available at: https://data.vision.ee.ethz.ch/cvl/DIV2K/
Training the data Medium resolution (172x172x3)
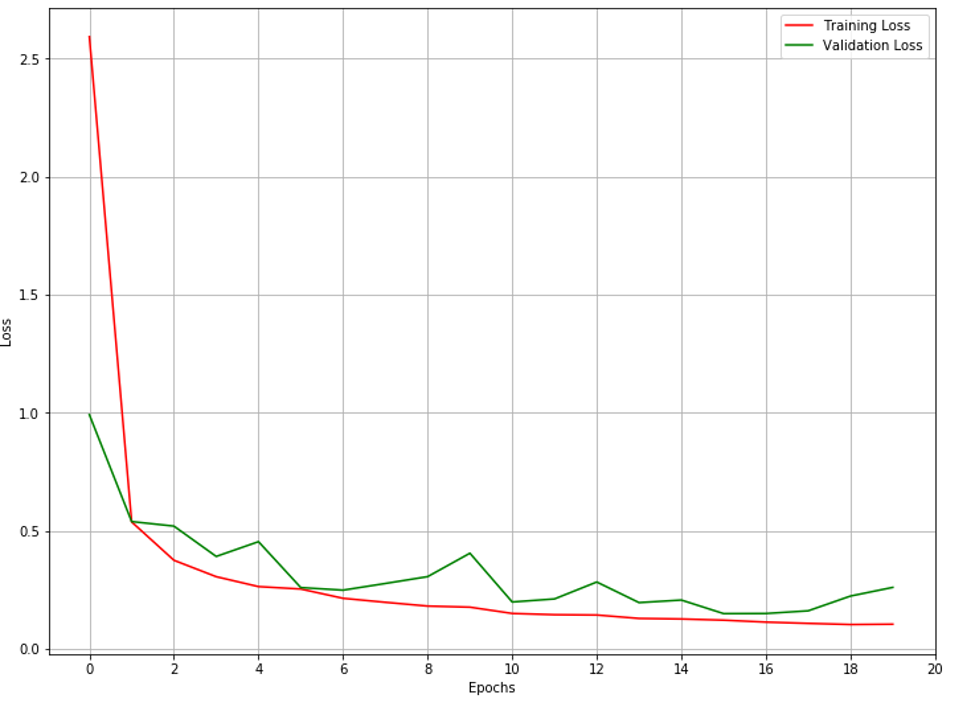
First I trained the first autoencoder using 172x172x3 images to represent the medium resolution images. Due to the limited computation power available, I had to limit the number of pixels that would be treated in the model. The images displayed in the graph below are validation samples at the end of the training epoch followed by the graph of the loss functions. For each pair of images, the top image is the original data and the bottom image is the reconstructed data through the model.

Training the data High resolution (344x344x3)
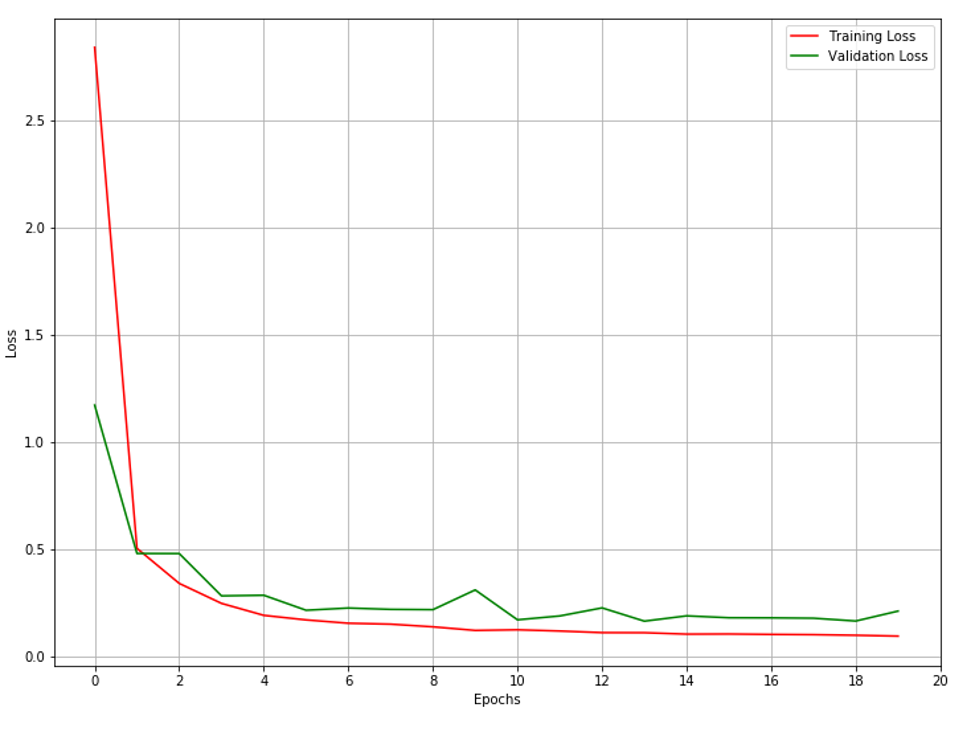
Same idea as in the previous section using high resolution images. For this case, I trained the second autoencoder using 344x344x3 images to represent the high resolution images. Again, the images displayed in the graph below are validation samples at the end of the training epoch followed by the graph of the loss functions. For each pair of images, the top image is the original data and the bottom image is the reconstructed data through the model.

Main idea is to Capture the features
Until now, both models are working fine. The first autoencoder successfully compressed the images to then reconstruct them with only a small loss. The second autoencoder performed similarly with high resolution images. The main idea here when using autoencoders is to capture the main features of the images while disregarding the noise.
Now, the next idea is to find a relation between the features collected from a high resolution image and the features of the same image in medium resolution.
- Encode an image using High resolution model
- Use the latent representation of this high resolution image and transform it into a representation of a medium resoultion image
- Decode this representation using the medium resolution model
To do so, I created a third model that would be placed between the two previous autoencoders. This new network would take the compressed representation of the high resolution image, adjust it, and feed it to the decoder of the medium resolution autoencoder. The idea here is that even though both autoencoders do not use the same weights, the latent representation of the same image in different resolutions should be similar. Therefore, using an additional neural network such as a simple multilayer perceptron we could transform the representation of the high resolution image to a representation of a medium quality image. Inevitably, some features of the high resolution image will be lost, but we should still be able to retrieve all the features of a medium quality image.
However when put in practice…
The results are not terrible. The figure below is the result of the compressed representation of high resolution images being processed through the multilayer perceptron and finally decoded using the medium resolution autoencoder to obtain reconstructed medium resolution images. However, the model struggles at converging even after multiple epochs of training. This is where I am at now.

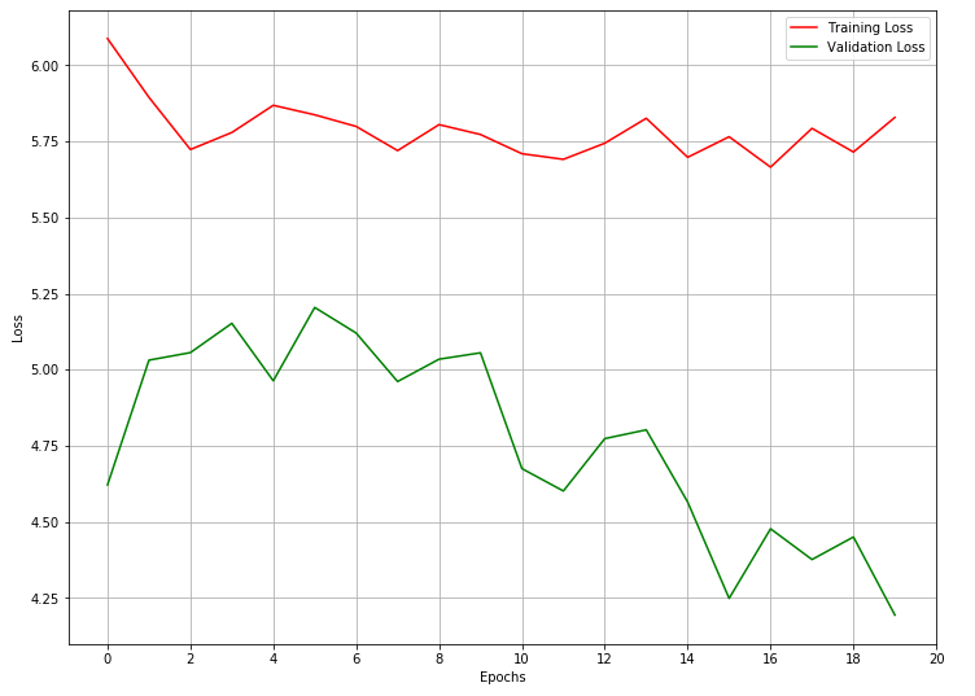
Solutions tried until now…
- Standardize and normalize the data
- Increase the capacity of the convolution network
- Have a fully connected layer in the middle
- Fine-tuning the modelsll
- Alternate between training the
- Train the medium resolution to be able to decode high resolution from the start
Have yet to try…
- Try with smaller data (3x32x32) or even smaller to infer new reasoning
- Variational autoencoders (VAE)